Hệ quả là, chỉ vài ngày kể từ khi AI Overviews chính thức được ứng dụng tại thị trường Mỹ, người dùng liên tục thông báo những ví dụ kết quả tổng hợp tìm kiếm bằng Gemini với nội dung kỳ quái. Có lúc nó “tư vấn” người dùng đổ keo lên pizza, rồi khuyên “ăn ít nhất 1 cục đá mỗi ngày”, hay thậm chí là thông tin nói rằng cố tổng thống Andrew Johnson mất năm 1875 nhưng lại nhận bằng đại học trong khoảng thời gian từ năm 1947 đến 2012.

Kết quả là phó chủ tịch mảng tìm kiếm trực tuyến, cô Liz Reid đã phải đưa ra tuyên bố chính thức rằng Google đang tạo ra những chỉnh sửa về mặt kỹ thuật để giúp AI Overviews bớt đưa ra những câu trả lời không chính xác về mặt thông tin. Trong đó bao gồm khả năng nhận diện những câu lệnh tìm kiếm vô nghĩa tốt hơn. Cùng lúc, hệ thống cũng sẽ giới hạn những câu trả lời từ AI mang ý nghĩa mỉa mai hay hài hước, và cả những nội dung do người dùng internet viết đùa vui.
Nhưng trên khía cạnh kỹ thuật, vì sao mãi đến bây giờ vẫn có tình trạng AI bị “loạn ngôn”, đưa ra những thông tin không chính xác như vậy?
AI Overviews hoạt động như thế nào?

LLM vận hành theo cách dự đoán những chuỗi văn bản kế tiếp nhau dựa trên những dữ liệu đầu vào trong quá trình huấn luyện AI. Vì ứng dụng tạo sinh vận hành theo dự đoán xác suất, nên văn bản chúng tạo ra trông có vẻ tự nhiên như văn viết của con người. Đổi lại, khả năng tạo ra những thông tin sai cũng rất cao. LLM không biết đâu là sự thật, đâu là thông tin chính xác, và đâu là thông tin sai lệch, nó chỉ nhận diện được văn bản có mượt và tự nhiên hay không mà thôi.
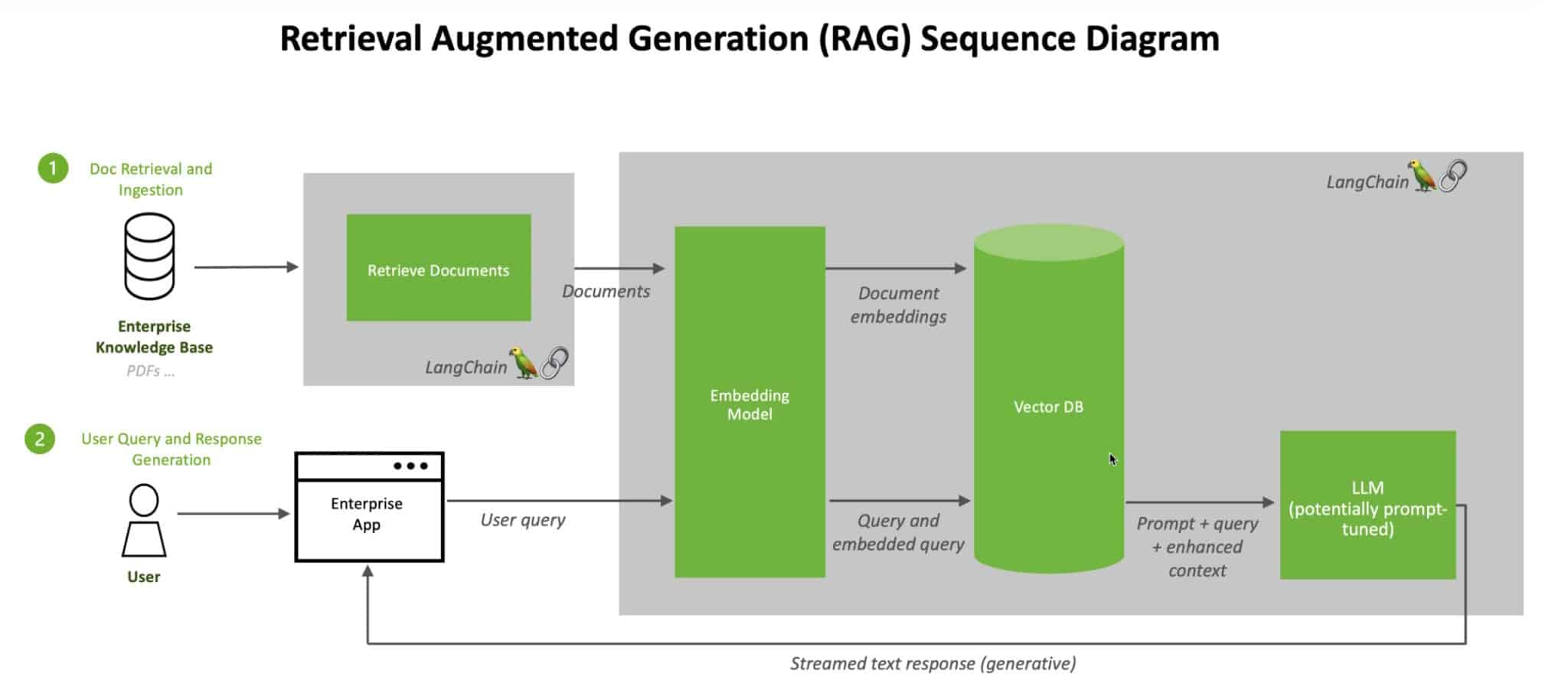
Rất có khả năng, để thu thập dữ liệu từ các trang web trên mạng internet, mô hình Gemini ứng dụng cho AI Overviews ứng dụng kỹ thuật RAG. Với kỹ thuật này, LLM có thể kiểm tra những nguồn thông tin cụ thể bên ngoài lượng dữ liệu đầu vào dùng để huấn luyện mô hình, ví dụ như những trang web và những bài viết được đăng tải sau này.

Khi người dùng gõ câu lệnh tìm kiếm, công cụ AI sẽ kiểm tra những tài liệu và văn bản, rồi tóm tắt chúng thành câu trả lời. Vì hệ thống AI có thể đối chiếu câu lệnh ban đầu với những phần trong một trang web, nó sẽ có thể dẫn nguồn thông tin mà công cụ đã tìm ra. LLM không thể làm được điều này, phải kết hợp LLM với RAG mới được.
Vì sao lại tạo ra những câu trả lời quái dị?
Nhưng vấn đề lại nằm ở chỗ, chính bản thân RAG cũng không hoàn hảo. Để LLM ứng dụng RAG tạo ra một câu trả lời có ích, thì bản thân kỹ thuật này cũng phải được đảm bảo sẽ tìm kiếm những nguồn thông tin chính xác trước, rồi mới đến đoạn tóm tắt thông tin và gửi tới người dùng. Nếu một trong hai bước tìm kiếm thông tin hoặc tạo sinh văn bản không vận hành ưng ý, lỗi sẽ xuất hiện.
Với ví dụ AI Overviews khuyên người dùng đổ keo lên pizza, RAG lấy thông tin từ một bài viết đùa vui trên mạng xã hội Reddit, vì có lẽ bài viết này có liên quan tới câu lệnh hỏi vì sao phô mai không dính lên đế bánh. Nhưng giữa quá trình đó, lỗi xuất hiện.

Theo giáo sư Chirag Shah của đại học Washington, chuyên môn về tìm kiếm trực tuyến: “Thông tin có liên quan không phải lúc nào cũng là thông tin đúng, và phần tạo sinh của AI Overviews không kiểm soát được mức độ chính xác của thông tin.”
Tương tự như vậy, nếu RAG tìm thấy những thông tin không đồng nhất và có quan điểm trái ngược, ví dụ như văn bản quy định và bản cập nhật mới nhất của văn bản quy định ấy, RAG sẽ không thể xác định đâu là thông tin chính xác và cập nhật nhất. Thay vào đó, RAG có thể sẽ kết hợp cả hai nguồn thông tin xung đột ấy, hệ quả là có khả năng tạo ra những câu trả lời sai.

Chủ đề tìm kiếm càng cụ thể, khả năng xuất hiện thông tin sai lệch sẽ càng cao trong kết quả tổng hợp của LLM. Vấn đề này có thể tạo ra những hậu quả xấu trong nhiều ngành như y khoa, giáo dục và khoa học.
Theo người phát ngôn của Google, trong nhiều trượng hợp, AI Overviews đưa ra thông tin sai lệch vì không có đủ thông tin hữu ích trên mạng internet để trả lời câu lệnh tìm kiếm của người dùng, hoặc câu lệnh quá gần với những bài viết mỉa mai châm biếm và hài hước. Cũng theo đó, hầu hết những câu lệnh AI Overviews vận hành đều trả kết quả chất lượng cao, và những câu trả lời sai lệch đều là kết quả của những từ khóa tìm kiếm kỳ quặc.
Theo Google, tỷ lệ AI Overviews đưa ra kết quả có hại, sai lệch hay không chấp nhận được là 1:7.000.000.
Lý do không chỉ đến từ dữ liệu huấn luyện AI
Dù rằng cái ví dụ “đổ keo lên pizza” là ví dụ được đề cập nhiều nhất khi nói đến vấn đề AI Overviews vẫn mắc tình trạng “loạn ngôn”, công cụ tìm kiếm lọc những thông tin từ những nguồn không đảm bảo chính xác. Thế nhưng vẫn có khả năng AI tổng hợp những nguồn đáng tin cậy mà vẫn tạo ra thông tin sai.
Nhà nghiên cứu Melanie Mitchell của viện nghiên cứu Santa Fe Institute, New Mexico, Mỹ đã thử Google cụm từ khóa “Mỹ có bao nhiêu tổng thống theo đạo Hồi”. AI Overviews trả lời: “Nước Mỹ có một tổng thống theo đạo Hồi, đó là Barack Hussein Obama.”

Ông Barack Obama không theo đạo Hồi, tức là thông tin của AI Overviews sai. Nhưng nguồn mà nó viện dẫn là một cuốn sách nội dung nghiên cứu hàn lâm có tiêu đề “Barack Hussein Obama: Tổng thống đạo Hồi đầu tiên của nước Mỹ?”
Hệ thống AI trong trường hợp này không chỉ hiểu sai toàn bộ nội dung cuốn cách, mà còn đưa ra thông tin trái ngược hoàn toàn so với nội dung nghiên cứu. Cô Mitchell cho biết: “Có vài vấn đề với AI ở đây. Tìm ra nguồn thông tin có giá trị và không phải nội dung châm biến là một. Nhưng vấn đề quan trọng hơn là AI phải diễn giải và tóm tắt chính xác nguồn thông tin nó tổng hợp được. Đó là thứ mà AI hiện giờ vẫn gặp khó khăn trong vận hành, ngay cả khi tìm ra nguồn thông tin chính xác, thì AI vẫn có thể tạo ra lỗi.”
Có giải quyết được tình trạng này?
Khẳng định quan trọng nhất ở đây là, AI hiện giờ hoàn toàn không đáng tin cậy 100%. LLM còn sử dụng kỹ thuật tạo sinh nhờ xác suất, để tạo những chuỗi từ và văn bản, thì “loạn ngôn” sẽ luôn là một nguy cơ đối với quá trình tìm kiếm thông tin. Dù Google có tinh chỉnh và nâng cấp Gemini vận hành AI Overviews đến đâu đi chăng nữa, thì cũng không thể chắc chắn đảm bảo thông tin mà công cụ này tổng hợp sẽ chính xác và đáng tin cậy 100%.
Google cho biết họ đang thêm những giới hạn được kích hoạt khi người dùng tìm kiếm những câu lệnh nơi AI Overviews không có khả năng tạo câu trả lời hữu ích. Bên cạnh đó là những hàng rào bảo vệ người dùng và lọc thông tin đối với những câu lệnh liên quan tới sức khỏe hay y học.
Cùng với đó, Google cũng có thể tạo ra những bước cải tiến kỹ thuật RAG, để đánh dấu những câu lệnh tìm kiếm có nguy cơ, hệ thống từ chối trả kết quả tìm kiếm nếu không đảm bảo thông tin chính xác.
Rồi những kỹ thuật khác như cải thiện khả năng tự học của mô hình AI dựa trên phản hồi của người dùng, kết hợp những phản hồi ấy vào quá trình huấn luyện LLM cũng sẽ cải thiện được chất lượng câu trả lời mỗi khi tìm kiếm thông tin.
Tương tự như vậy, LLM có thể được huấn luyện chuyên biệt chỉ cho tác vụ xác định câu hỏi liệu có thể được trả lời một cách hiệu quả hay không. LLM khi ấy sẽ phải xác định chất lượng nguồn thông tin một cách cẩn trọng, trước khi tạo sinh nội dung cho người dùng.