Vừa qua StabilityAI đã chính thức tung ra checkpoint dạng safetensor của Stable Diffusion 3, phiên bản Medium với 2 tỷ tham số, tức là hoàn toàn đủ khả năng vận hành trên những hệ thống máy tính cá nhân.

Ở thời điểm hiện tại, Stable Diffusion 3 đang vận hành ổn thông qua nền tảng ComfyUI, còn Automatic1111 WebUI thì vẫn chưa hỗ trợ vận hành mô hình tạo sinh hình ảnh bằng thuật toán AI này. Lý do là bên cạnh mô hình gốc, Stable Diffusion 3 còn có thêm vài mô hình chuyên biệt để xử lý ký tự và văn bản trên tấm hình mà nó tạo ra. Nhờ đó, theo StabilityAI, khả năng tạo ký tự văn bản (text encoder) trong hình sẽ chính xác và mạnh hơn nhiều so với những giải pháp khác đang có như DALL-E 3 hay Midjourney v6.
Stable Diffusion 3 vận hành thế nào?
Không giống như Stable Diffusion XL, SD3 được thiết kế lại kiến trúc để trở thành một mô hình đa chế độ, không chỉ hiểu được ngôn ngữ mà còn hiểu được cả chi tiết hình ảnh đầu vào để thực hiện quá trình nội suy, tạo ra những hình ảnh mới. Kiến trúc mới này gọi là MMDiT, Multimodal Diffusion Transformer. SDXL hay những phiên bản Stable Diffusion trước đó không được ứng dụng MMDiT.
Theo các nhà nghiên cứu của StabilityAI, văn bản và hình ảnh là hai thứ ngôn ngữ tự nhiên khác biệt, nên phải sử dụng hai gói weight khác nhau để xác định nội dung của hai chế độ dữ liệu đầu vào này. Điều này đồng nghĩa với việc, Stable Diffusion 3 sẽ có hai transformer độc lập, kết hợp với nhau để vận hành.

Nhờ đó, thông tin đầu vào của người dùng ra lệnh cho SD3 tạo hình bằng AI sẽ có thể chuyển qua lại tự do giữa văn bản và hình ảnh, từ đó giúp hình ảnh vừa chân thực, ký tự trong những tấm hình cũng chính xác hơn trong mắt con người.
Thêm nữa, quy trình tạo sinh hình ảnh cũng được xử lý thông qua công thức Rectified Flow mới, dữ liệu và “hình nhiễu” kết nối một cách tuyến tính trong quá trình huấn luyện mô hình. Kết quả ngắn gọn của quy trình nghiên cứu và phát triển này, là quá trình nội suy đơn giản hơn, tức là anh em có thể tạo ra những tấm hình ưng ý với số bước nội suy thấp hơn, chỉ khoảng 30 đến 50 bước là hình đã đủ đẹp cũng như chân thực. Đó là tuyên bố của StabilityAI trong văn bản công bố thành quả nghiên cứu SD3 hồi tháng 3 vừa rồi.

Xét riêng tới phiên bản SD3 Medium với 2 tỷ tham số, được huấn luyện dựa trên 1 tỷ tấm hình chụp, rồi huấn luyện nâng cao dựa trên khoảng 30 triệu hình ảnh chất lượng cao, anh em sẽ có vài lựa chọn model AI, có hoặc không có text encoder T5 tích hợp để render chữ hợp lý và chính xác trong quá trình tạo sinh hình ảnh. Encoder tích hợp này có dung lượng chừng 4GB, 4.7 tỷ tham số, tương đối nặng đối với cấu hình máy tính cá nhân. Đây là chi tiết rất quan trọng để đảm bảo những thế mạnh của SD3 vận hành hoàn hảo.

Bên cạnh SD3 Medium vừa ra mắt, sẽ có SD3 Small với 1 tỷ tham số, SD3 Large với 4 tỷ tham số, và SD3 Huge với 8 tỷ tham số, cấu hình máy tính nào cũng có thể tạo sinh mà không cần tới sự trợ giúp của những máy chủ đám mây.
Làm thế nào chạy SD3 trên máy tính?
Như đã đề cập, hiện tại SD3 không chạy được trên Automatic1111 WebUI vì cần ghép thêm không chỉ 1 mà tới 3 clip text encoder có dung lượng lần lượt 234 MB, 1.3 và 4.7GB. Và ở thời điểm hiện tại, ComfyUI, một nền tảng giao diện web vận hành code python khác lại đang hỗ trợ vận hành hoàn hảo Stable Diffusion 3. Nên thành ra chúng ta sẽ chuyển qua ComfyUI để dùng thử mô hình AI tạo hình mới nhất này.

Dùng Stable Diffusion XL tạo hình bằng AI: Yêu cầu phần cứng PC rất cao, nhưng hình thì rất đẹp
Nếu anh em chưa cài ComfyUI hay thậm chí là còn chưa cài Automatic1111 (tức là trong máy tính chưa có Python và Git), thì mình xin phép liệt kê cụ thể các bước để cài ComfyUI, rồi kế đến mới là tải mô hình SD3 để bắt đầu tạo hình. Khi cài ComfyUI, máy sẽ cài luôn cho anh em những phần mềm có liên quan và cần thiết, không phải thực hiện nhiều bước như Automatic1111.
- Truy cập trang GitHub của ComfyUI: https://github.com/comfyanonymous/ComfyUI
- Ấn nút tải file nén bản cài ComfyUI trên trang web này tại đây: https://github.com/comfyanonymous/ComfyUI/releases/download/latest/ComfyUI_windows_portable_nvidia_cu121_or_cpu.7z
- Giải nén vào vị trí anh em muốn, trong ổ C, D hoặc bất kỳ đâu, kể cả ngoài Desktop.
- ComfyUI vận hành tốt nhất trên card đồ hoạ Nvidia, nên sau khi giải nén xong, anh em sẽ click vào file run_nvidia_gpu.bat để khởi chạy hệ thống. Những anh em đang sử dụng card đồ hoạ của AMD sẽ cần tải bộ tập lệnh vận hành nhân GPU do AMD phát triển, là ROCm chứ không có nhân CUDA để chạy, rồi cũng phải tải thêm pytorch và pip để chạy ComfyUI tạo hình bằng AI. Một điểm nữa cần nhấn mạnh, muốn tạo hình bằng SD3 thông qua ComfyUI, phải cài Linux chứ không chạy được trên Windows. Chi tiết anh em có thể tham khảo cụ thể nhất ở trang GitHub của ComfyUI.
- Sau khi khởi chạy xong, ra được màn hình chính của ComfyUI trên trình duyệt ở địa chỉ 127.0.0.1:8188, anh em đóng cả trình duyệt lẫn cửa sổ command prompt, rồi tìm tới folder ComfyUI_windows_portable/Update và chạy file bat tên là update_comfyui_and_python_dependencies.
- Bước này rất quan trọng vì ComfyUI sẽ cập nhật những node rất cần thiết để vận hành SD3, chẳng hạn như node TripleCLIPLoader chẳng hạn. Chạy xong thì anh em đóng cửa sổ command prompt lại.
- Giờ là lúc tải mô hình SD3.
Tải mô hình SD3
Để tải mô hình Stable Diffusion 3 về máy tính, anh em truy cập trang này: https://education.civitai.com/quickstart-guide-to-stable-diffusion-3/. Ở đó anh em sẽ thấy 7 mô hình khác nhau:

Quickstart Guide to Stable Diffusion 3 – Civitai Education
- SD3 Medium 4.2GB
- SD3 Medium + Clips 5.8GB
- SD3 Medium + CLips T5XXL FP8 10.6GB
- Text Encoder Clip L 234MB
- Text Encoder Clip G 1.3GB
- Text Encoder t5xxl_fp8_e4m3fn 4.7GB
- Text Encoder t5xxl_fp16 9.5GB
Anh em sẽ cần tải 4 file để bắt đầu làm hình bằng SD3: SD3 Medium, Text Encoder Clip L, Text Encoder Clip G, và Text Encoder t5xxl_fp8_e4m3fn.
Sau khi tải xong 4 file này, anh em bắt đầu bỏ file safetensors SD3 Medium vào folder ComfyUI/models/checkpoints, và ba file còn lại đều bỏ vào folder ComfyUI/models/clip/.
Bước kế tiếp là tải workflow để giao diện ComfyUI biết phải xử lý mô hình Stable Diffusion 3 ra sao. Anh em vào trang web này: https://civitai.com/models/497255?modelVersionId=568256, và tải fole zip nặng 8kB về máy, giải nén sẽ ra ba file json. Sử dụng file workflow này rất đơn giản.
Stable Diffusion 3 (SD3) – ComfyUI Workflows | Stable Diffusion Checkpoint | Civitai
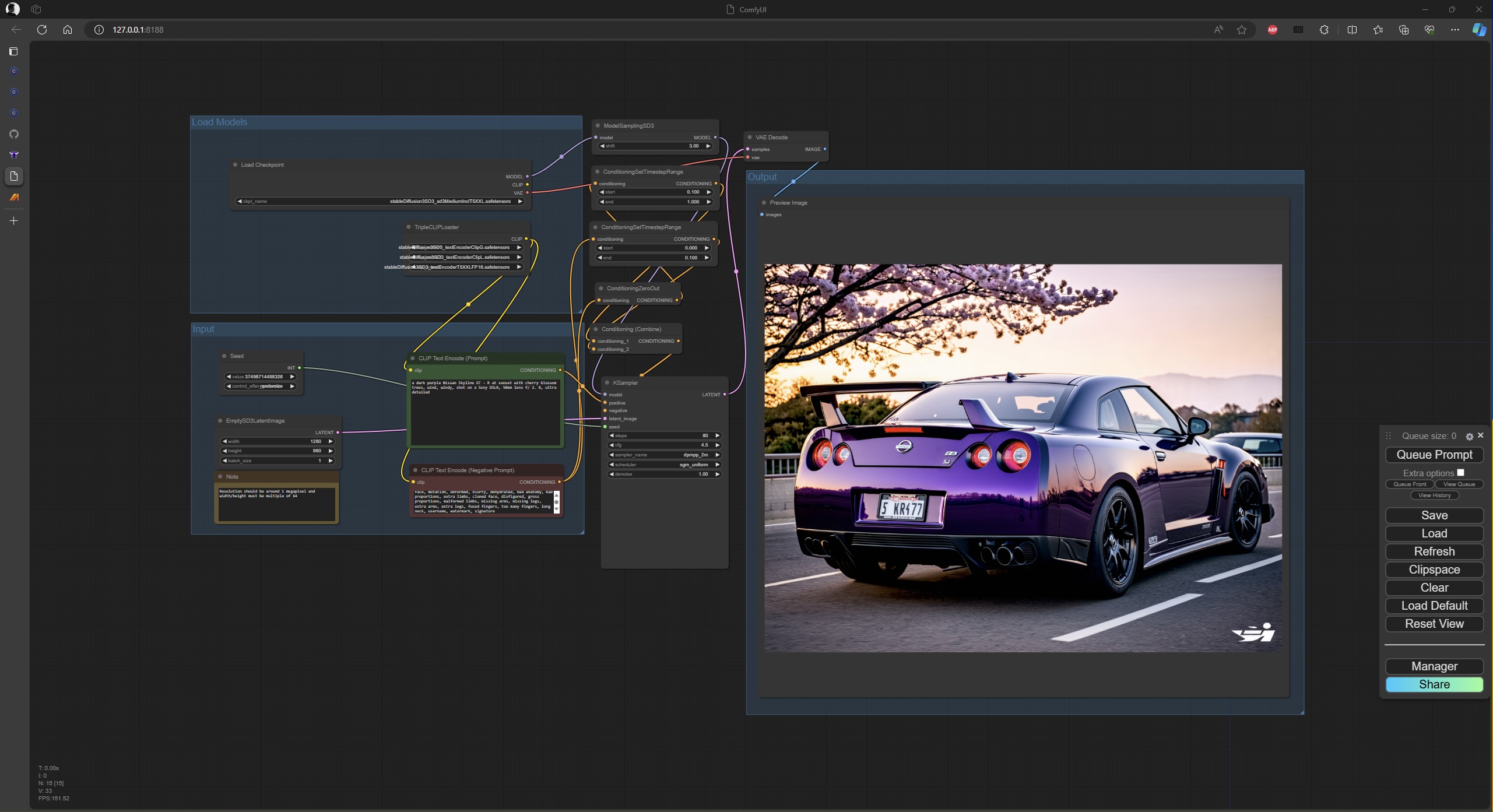
Anh em mở ComfyUI bằng file run_nvidia_gpu.bat lên, sau khi ra giao diện ComfyUI trong trình duyệt, anh em kéo thả một trong ba file json vào, chẳng hạn như workflow cơ bản chỉ có tuỳ chọn prompt đơn, bao gồm positive và negative prompt như dưới đây, trang web sẽ tự động tải cho anh em, trông như thế này là bắt đầu tạo hình được:
Theo StabilityAI, card đồ hoạ chỉ cần 6 đến 8GB là chạy được rồi, khi kết hợp với việc chuyển bớt mô hình qua RAM và CPU. Còn những card đồ hoạ với dung lượng 12GB trở lên là vận hành hoàn hảo, không phải bỏ bớt Text Encoder vào RAM.
Trải nghiệm SD3: Chất lượng hình ảnh, tốc độ xử lý…
Tất cả những tấm hình demo mình đăng trong bài viết này đều được làm dựa trên những tuỳ chọn tham số cố định như thế này:
- Độ phân giải 960×1280 pixel hoặc 1280×960 pixel
- Steps: 80
- CFG: 4.5
- Seed: Random
- Sampler: DPMPP_2M
- Scheduler: SGM_Uniform
- Denoise: 1.0






Rất dễ nhận ra một đặc tính của Stable Diffusion 3. Nếu như chất lượng hình ảnh và chi tiết nhân vật cũng như vật thể có những nâng cấp nhẹ, thì khả năng Encode văn bản và ký tự ngôn ngữ của SD3 là một bước cải tiến rất lớn so với SDXL hay SD 1.5. Thậm chí trong một số trường hợp, đúng là khả năng nhận diện và tạo sinh ký tự chữ cái ấn tượng hơn DALL-E 3 và Midjourney v6 thật.

Ấn tượng thứ hai của mình là, với 2 tỷ tham số, vận hành Stable Diffusion 3 đúng là tương đối nhẹ. Mọi tấm hình trong bài viết này đều được tạo ra trong khoảng thời gian dưới 30 giây với 80 bước nội suy. Còn nếu chỉnh xuống 40 đến 50 bước nội suy, có khi chỉ mất 15 giây là có một tấm hình kích thước vừa đủ rồi.

Hồi giới thiệu Stable Diffusion 3, StabilityAI nói rằng mô hình này vận hành với RTX 4090 24GB VRAM tạo hình mất khoảng hơn 30 giây cho mỗi tấm hình độ phân giải 1024×1024 pixel. Có lẽ họ thử nghiệm phiên bản mạnh nhất, nhiều tham số nhất của SD3 với 8 tỷ tham số. Còn với thử nghiệm của mình, với RTX 4080 16GB RAM, 2 tỷ tham số là vừa vặn để tạo ra những tấm hình độ phân giải 960×1280 pixel rất nhanh, gần như không phải chờ đợi gì nhiều, chỉ mất thời gian tinh chỉnh câu lệnh để tạo hình sao cho ưng ý nhất.

Vài đánh giá khác về SD3 như thế này:
- So sánh với DALL-E 3, cách nhân vật con người tương tác với vật thể trong hình vẫn chưa so sánh được về mức độ chân thực.
- Càng nhiều vật thể xung quanh nhân vật chính của tấm hình, thì phong cách định sẵn của tấm hình theo lệnh của người dùng lại càng không được AI tuân theo.
- Vì cách vận hành mới, tạo hình bằng những cụm từ khóa rời rạc ngăn cách bằng dấu phẩy sẽ không hiệu quả bằng những câu lệnh dài, chi tiết và tự nhiên về mặt ngôn ngữ.
- Kết hợp những concept hình ảnh lại với nhau thực sự rất khó.
- Hình ảnh tạo ra bằng mô hình AI dễ dính artifact do phụ thuộc vào CogVLM trong quá trình đặt tên vật thể ở mỗi tấm hình trong dataset sử dụng để huấn luyện mô hình Stable Diffusion 3.
- Nếu anh em tạo hình bằng SDXL gặp khó khăn trong việc tạo những khung cảnh hình ảnh phức tạp, thì SD3 cũng không ngoại lệ. SD3 hiểu và làm theo câu lệnh tốt hơn rất nhiều, lấy điều kiện câu lệnh ngắn hơn 77 token (từ hoặc chuỗi từ), dài hơn thì AI sẽ bị khó hiểu.

Bàn tay của nhân vật thì lúc đẹp lúc xấu. Có lúc những ngón tay đặt ở những vị trí rất chính xác và tự nhiên, nhưng cũng có lúc trông rất quái dị, không thể nhận ra được là bàn tay. Cái này là thứ mà Stable Diffusion đến tận thời điểm này vẫn chưa giải quyết được tận gốc. Một ví dụ bàn tay không hoàn hảo:

Đổi lại, việc kiểm soát phong cách mỹ thuật của từng tấm hình, dù là phong cách ảnh chụp chân thực hay hình ảnh tranh vẽ theo nhiều phong cách hội hoạ khác nhau đã trở nên vô cùng hiệu quả, không phải chờ tới lúc những nhà phát triển tự do sử dụng mô hình safetensor gốc của SD3 để tiếp tục huấn luyện mô hình, tạo ra những mô hình mới phù hợp hơn với nhiều nhu cầu.

Tổng kết lại, SD3 sở hữu một kiến trúc nội suy và transformer mới để tạo hình bằng thuật toán AI, dựa trên hàng tỷ tấm hình trước đó mô hình AI đã được huấn luyện. Trước đó, StabilityAI đã tung ra Stable Cascade, một giải pháp tạo sinh hình ảnh đơn giản vận hành dựa trên kiến trúc tương tự. Nhưng dựa vào trải nghiệm của bản thân mình trong cả ngày vừa rồi, SD3 vẫn còn một số khiếm khuyết về khả năng nhận diện và hiểu nội dung câu lệnh, cũng như không phải lúc nào cũng hiểu chính xác bố cục và chi tiết tấm hình.